
Blog
Page 12 of 46
All Articles
Insights on AI, machine learning, and technology strategy
Small Business AI·
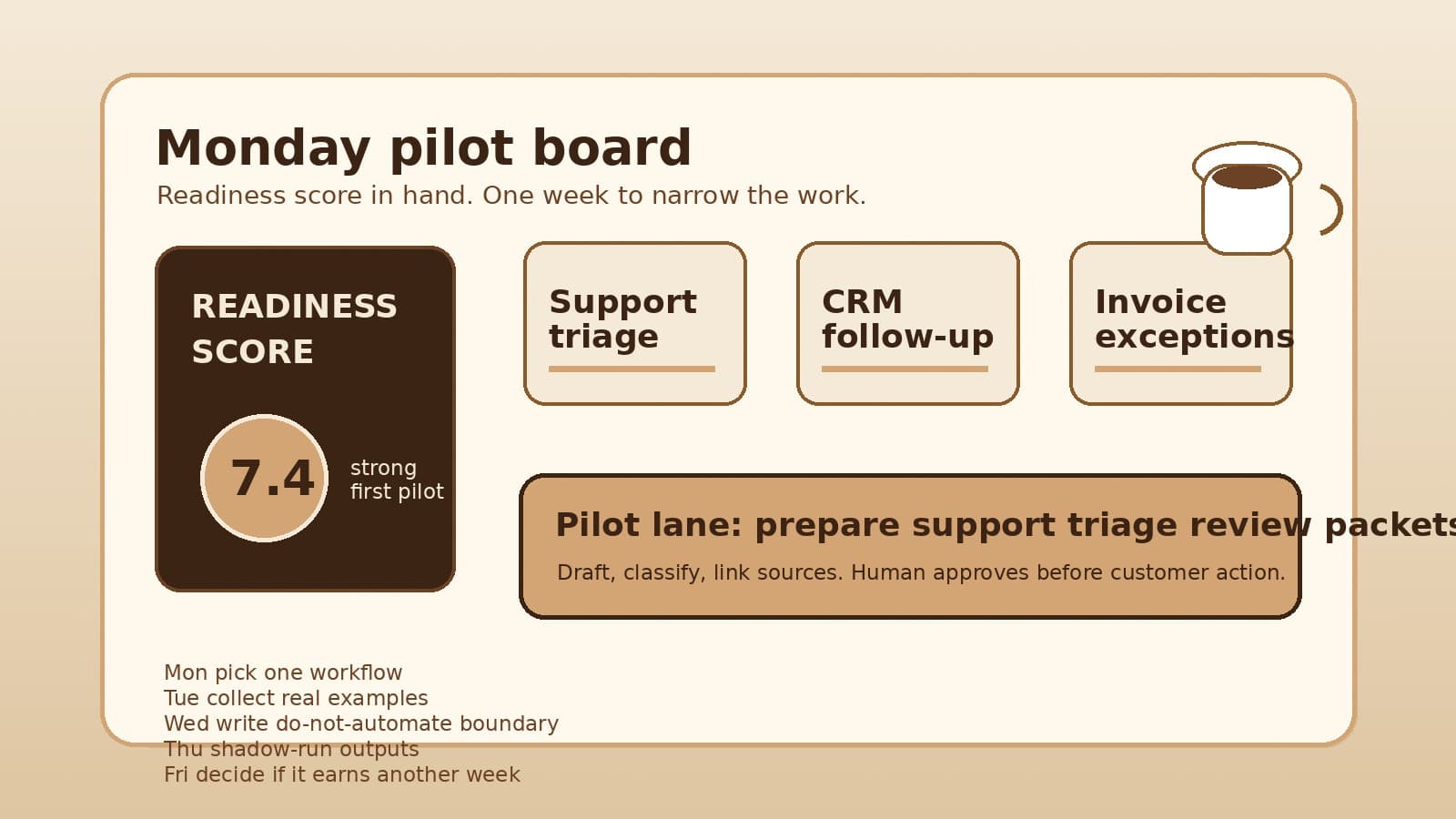
After the readiness score: what to do in the next seven days
Turn an AI workflow readiness score into a practical seven-day plan: choose one workflow, collect real examples, set boundaries, shadow-run outputs, and decide whether the pilot deserves another week.
7 min read

Technical Tutorials·
Write the AI approval policy before you choose the agent
Before comparing AI agent platforms, write the one-page approval policy that says what the system may read, draft, change, send, escalate, and log.
7 min read

Technical Tutorials·
Your AI agent needs a regression suite, not another demo
Production agents fail in traces, tool calls, approval logs, and edge cases. The useful teams turn those failures into regression tests.
8 min read

AI Development·
GitHub's Accessibility Agent Worked Because the Mess Was Already Organized
GitHub's experimental accessibility agent shows the real prerequisite for useful accessibility automation: structured issues, WCAG metadata, acceptance criteria, and human review habits.
7 min read

AI Development·
ITBench-AA shows why enterprise IT agents need receipts before root access
ITBench-AA shows a familiar enterprise AI failure mode: agents can investigate Kubernetes incidents plausibly, then confuse symptoms for root causes. Before teams let agents touch infrastructure or workflows, they need receipts, scope, approvals, escalation, and replayable evals.
8 min read

AI Development·
Your AI dashboard needs a quality lane, not just GPU charts
A green inference dashboard can still miss the failure that matters: the model is fast, available, and wrong. Production AI teams need to monitor both infrastructure quantity and output quality.
7 min read

AI Development·
Codex is moving AI coding agents into the customer feedback loop
Braintrust and Endava show a more useful pattern for AI coding agents: faster movement from customer request to preview branch, working spec, sandbox run, or reviewable delivery artifact.
8 min read

AI Development·
OpenAI's eval playbook makes the harness part of the result
A 92% success rate is not enough to approve an AI agent pilot. Teams need to know what tools, retries, prompts, budgets, safeguards, and receipts produced the score.
8 min read
Small Business AI·
The weekly workflow audit: how to find the first safe AI pilot
A practical weekly workflow audit helps small-business teams find the first AI pilot that is repeated, reviewable, reversible, and safe enough to learn from.
8 min read

AI Development·
Your AI Agent Needs a Bug Cemetery, Not Another Demo
AWS Bedrock AgentCore datasets point to a practical habit for reliable agents: turn production failures into versioned regression tests with locked inputs, expected tool calls, assertions, and CI gates.
7 min read

Industry Insights·
AML alert triage shows the real shape of enterprise AI automation
AWS and Snowflake's AML triage walkthrough shows a practical AI automation pattern: assemble evidence, produce a structured brief, and keep regulated decisions with humans.
6 min read

AI Development·
Enterprise IT agents just got a harder benchmark. The best models still missed half the incidents.
ITBench-AA shows why enterprise IT agents need scoped pilots, workflow receipts, eval datasets, approval gates, and human escalation before they touch production systems.
8 min read
Explore by Topic
Dive deeper into the subjects that matter to you

AI Development
Implementation notes for building AI tools around real business data, handoffs, review queues, and safeguards.
76

Announcements
Product notes, service updates, and BaristaLabs news that affect how small teams use AI at work.
7
Industry Insights
AI market news translated into workflow decisions, risk boundaries, and practical next steps for small businesses.
356

Machine Learning
Model concepts explained through thresholds, queues, and error costs that small teams can actually manage.
10

Small Business AI
Plain-language guidance for owners and operators choosing one useful, reviewable AI workflow at a time.
82
Technical Tutorials
Hands-on guides for approval policies, shadow weeks, agent receipts, and other AI workflow controls.
11