
Blog
Page 4 of 44
All Articles
Insights on AI, machine learning, and technology strategy
Industry Insights·
Your agent audit log needs a rehearsal, not a promise
RootSign shows why agent audit logs need rehearsal. The chain may verify cleanly, but concurrency, retries, redaction, and tamper tests still deserve a deliberate break-it-first run.
6 min read

Industry Insights·
Don't ask an AI if you're audit-ready. Put it in a read-only room.
A small open-source project turns a coding agent into a read-only compliance auditor. The reusable idea isn't the prompt. It's the room you run it in.
9 min read

Industry Insights·
Your agent stack needs a switchboard, not another brain
The hard part of multi-agent work is not picking a framework. It is the traffic between agents after one request fans out. Here is a copyable ledger for watching it.
9 min read

Industry Insights·
Your SBOM stops before the agent starts
A clean npm audit does not mean a clean workstation. MCP servers, plugins, and skills can sit outside the review. The Agent BOM intake note catches them.
9 min read

AI Development·
Give the agent a ticket, not the key
When an AI agent needs Stripe access, the default move hands it the raw key. A better pattern gives it a secret handle, a host allowlist, and a daemon that owns the call. Here is the courier policy that makes that concrete.
9 min read
Industry Insights·
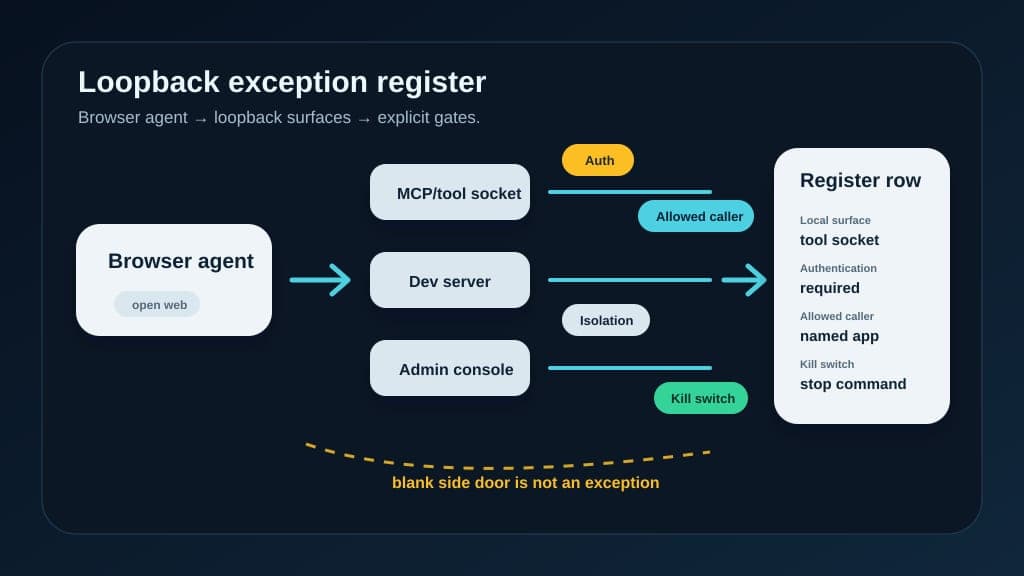
Localhost is not a sandbox when the agent can browse
AutoJack turned a single web page into a host-level code execution path through a local agent control socket. The useful lesson is not panic about one pre-release bug. It is that loopback stops being private when a browsing agent shares a host with privileged local services.
6 min read

AI Development·
The AI contribution label belongs in the commit, not the meeting notes
You run git log and the last line of the commit reads Co-authored-by: Claude. It shows up in the contributors list like a teammate who just joined. It isn't one. That gap is the whole post.
7 min read

Industry Insights·
Give the agent a boarding pass, not a badge
A background coding agent finishes a Worker and hits a sign-in wall. The risky fix is a permanent login. Cloudflare's temporary accounts point at a narrower one: disposable authority plus a claim ticket with a deadline.
7 min read

Industry Insights·
You can't govern an agent you can't name
A company cannot protect a swarm it has not counted. NeuralTrust's $20M raise is a signal that agent security is becoming infrastructure, but the first useful artifact is still a roster.
7 min read

AI Development·
AGENTS.md tells AI how to work. AGENTOWNERS tells it where to stop.
A coding agent opens one pull request that fixes a doc typo and edits your auth code in the same branch. The instructions file was polite. The repo still has to decide. That gap is what AGENTOWNERS is trying to close.
7 min read

AI Development·
Before an AI agent queries production, build the query leash
Operators are calling direct database access for AI agents a nightmare, and the MCP docs keep adding read-only switches for a reason. The fix is a small boundary you write before the agent gets the connection string.
6 min read

AI Development·
The automation cassette is the missing artifact for web agents
A new open-source tool watches you browse and writes the script. The useful part is not the agent. It is the recording: an automation cassette your team can replay, review, and repair.
8 min read
Explore by Topic
Dive deeper into the subjects that matter to you

AI Development
Implementation notes for building AI tools around real business data, handoffs, review queues, and safeguards.
73

Announcements
Product notes, service updates, and BaristaLabs news that affect how small teams use AI at work.
7
Industry Insights
AI market news translated into workflow decisions, risk boundaries, and practical next steps for small businesses.
343

Machine Learning
Model concepts explained through thresholds, queues, and error costs that small teams can actually manage.
10

Small Business AI
Plain-language guidance for owners and operators choosing one useful, reviewable AI workflow at a time.
81
Technical Tutorials
Hands-on guides for approval policies, shadow weeks, agent receipts, and other AI workflow controls.
10