Industry Insights369 articles · Page 13 of 31
Industry Insights
AI market news translated into workflow decisions, risk boundaries, and practical next steps for small businesses.
Industry Insights articles, page 13

Industry Insights
The MCP token tax no one quoted: 44,000 tokens to check one repo language
A controlled benchmark found MCP costing 4 to 32× more tokens than CLI for identical operations. NVIDIA's Vera CPU launched with 88 custom cores and 22,500 concurrent agent environments per rack. Mistral's Leanstral beat Claude Sonnet 4.6 on formal proof benchmarks at one-fifteenth the price.
5 min read

Industry Insights
Mistral and Nvidia just put a 675B model on a 41B budget
Mistral AI joined Nvidia's Nemotron Coalition at GTC 2026 and helped build the open base model behind Nemotron 4. The headline number is 675B parameters, but the practical number is 41B active per query.
4 min read

Industry Insights
Nvidia's 35x inference number lost its denominator on the way to the headline
Nvidia's Groq 3 LPX claims 35x inference throughput, but the unit is per megawatt, not absolute. The real story is 128GB of on-chip SRAM replacing HBM entirely — a supply chain end-run hiding inside a performance slide.
4 min read

Industry Insights
`safe_mode=True` got its first CVEs. The Hugging Face scanner missed them.
Researchers found six zero-day vulnerabilities in ML model loading, including the first CVEs ever assigned to Keras safe_mode. Over 90% of non-security ML practitioners believed safe_mode=True prevented arbitrary code execution. It did not.
3 min read

Industry Insights
OpenAI Codex Subagents Turn One Coding Task Into a Coordination Problem
OpenAI shipped subagents in Codex on March 16, 2026, making parallel agent workflows available in both the app and CLI. The real change is not raw speed; it is that one coding task can now be split into delegation, review, and merge discipline.
5 min read

Industry Insights
$1.5 million would be unremarkable if both researchers weren't publishing in the same journals
An NBER working paper linked academic publication records to U.S. Census Bureau earnings data. The top 1% of AI scientists in industry now earn $1.5 million more per year than comparable academics — a fivefold increase since 2001.
4 min read
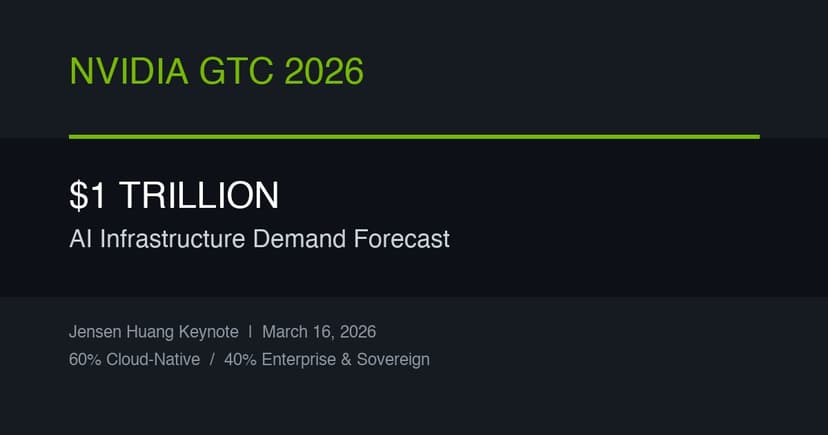
Industry Insights
Nvidia GTC 2026: The $1 Trillion Demand Signal
Jensen Huang doubled his AI infrastructure demand forecast to $1 trillion through 2027 at GTC 2026. The 60/40 cloud-to-enterprise split and his comments on inference reflection reshape planning assumptions for anyone building on AI.
5 min read

Industry Insights
AMD Wants the Next PC Cycle to Be an Agent Computer Cycle
AMD is no longer talking about AI PCs as glorified copilots. Its latest framing points toward 'Agent Computers': local-first machines built to keep autonomous AI workloads running continuously instead of waiting for a prompt.
5 min read

Industry Insights
Anthropic Crossed $19 Billion in Annual Revenue. The Enterprise AI Race Just Changed Hands.
Anthropic hit $19B in annual revenue run rate — jumping from $9B to $19B in ten weeks — while its share of U.S. enterprise AI spending surged from 4% to 40% in one year. The company that was an also-ran in enterprise is now the frontrunner.
5 min read

Industry Insights
AI Insurance Splits Into Two Camps: Cover Hallucinations or Exclude AI Entirely
AI liability insurance is splitting fast: some insurers now cover hallucinations and malfunctions, while others are writing absolute AI exclusions into legacy policies.
5 min read

Industry Insights
Five dimensions mattered more than the chatbot demos
More than 80 vendors applied to NATO’s Maven Smart System industry day, four were selected, and the teams had three weeks to integrate. Add Amazon’s five-dimensional Alexa tuning, Google’s 50-language Chrome push, and Meta’s MTIA roadmap, and the real signal was packaging, not raw model theater.
4 min read

Industry Insights
$167 per finished minute: the production cost hiding inside $2 AI video clips
A creative director spent $1,000 on Seedance 2.0 and got six minutes of footage. Per-clip generation ran $2–7, but re-rolls and a broken Continue Video feature pushed the real cost to $167 per finished minute.
4 min read
Explore Other Categories

AI Development
Implementation notes for building AI tools around real business data, handoffs, review queues, and safeguards.
106 articles

Announcements
Product notes, service updates, and BaristaLabs news that affect how small teams use AI at work.
7 articles

Machine Learning
Model concepts explained through thresholds, queues, and error costs that small teams can actually manage.
11 articles

Small Business AI
Plain-language guidance for owners and operators choosing one useful, reviewable AI workflow at a time.
88 articles
Technical Tutorials
Hands-on guides for approval policies, shadow weeks, agent receipts, and other AI workflow controls.
12 articles