
A confidence score feels like a decision waiting to happen.
If the model is 92% confident, approve it. If it is 61% confident, send it to a human. If it is below 40%, reject it. Clean, measurable, easy to explain.
Also dangerous if you treat it as policy.
Confidence scores can help route work. They can help prioritize review. They can make a messy approval queue easier to manage. But a confidence score is not the same thing as business risk, customer impact, regulatory exposure, or cost of being wrong.
That distinction matters when AI moves from recommendations into workflows.
Confidence answers a narrow question
In classic machine learning, a confidence-like score often represents how strongly a model favors one class over another. Google's Machine Learning Crash Course teaches classification with concepts like thresholds, confusion matrices, precision, recall, and related metrics. Those tools are useful because they force you to ask what kinds of mistakes the model makes.
But the score is still about the model's prediction. It is not a full description of the situation.
A support classifier may be 96% confident that a ticket is a billing issue. That does not tell you whether the customer is angry, whether the account is strategic, whether the requested change is reversible, or whether the next action touches money.
A lead-scoring model may be confident that an account is high intent. That does not tell you whether outreach should be automated, whether the contact opted in, or whether the sales team already has context from a private conversation.
The model score is one signal. The approval policy needs more than one signal.
Thresholds move errors around
Raising a threshold does not make a model safe. It changes which errors you see.
If you require 95% confidence before an AI system auto-routes support tickets, you may reduce wrong automatic routes. You may also create a large manual queue of tickets the system could have handled safely.
If you lower the threshold to 70%, the queue shrinks. But now more wrong routes reach customers or internal teams.
Neither threshold is correct in isolation. The right threshold depends on the cost of each kind of error.
For a low-risk internal tag, a false positive may be harmless. For a refund approval, the same error could cost money and trust. For a compliance-sensitive workflow, a false negative may be worse than a false positive because missing a risk is more expensive than reviewing an extra case.
This is why precision and recall are operational choices, not just model metrics.
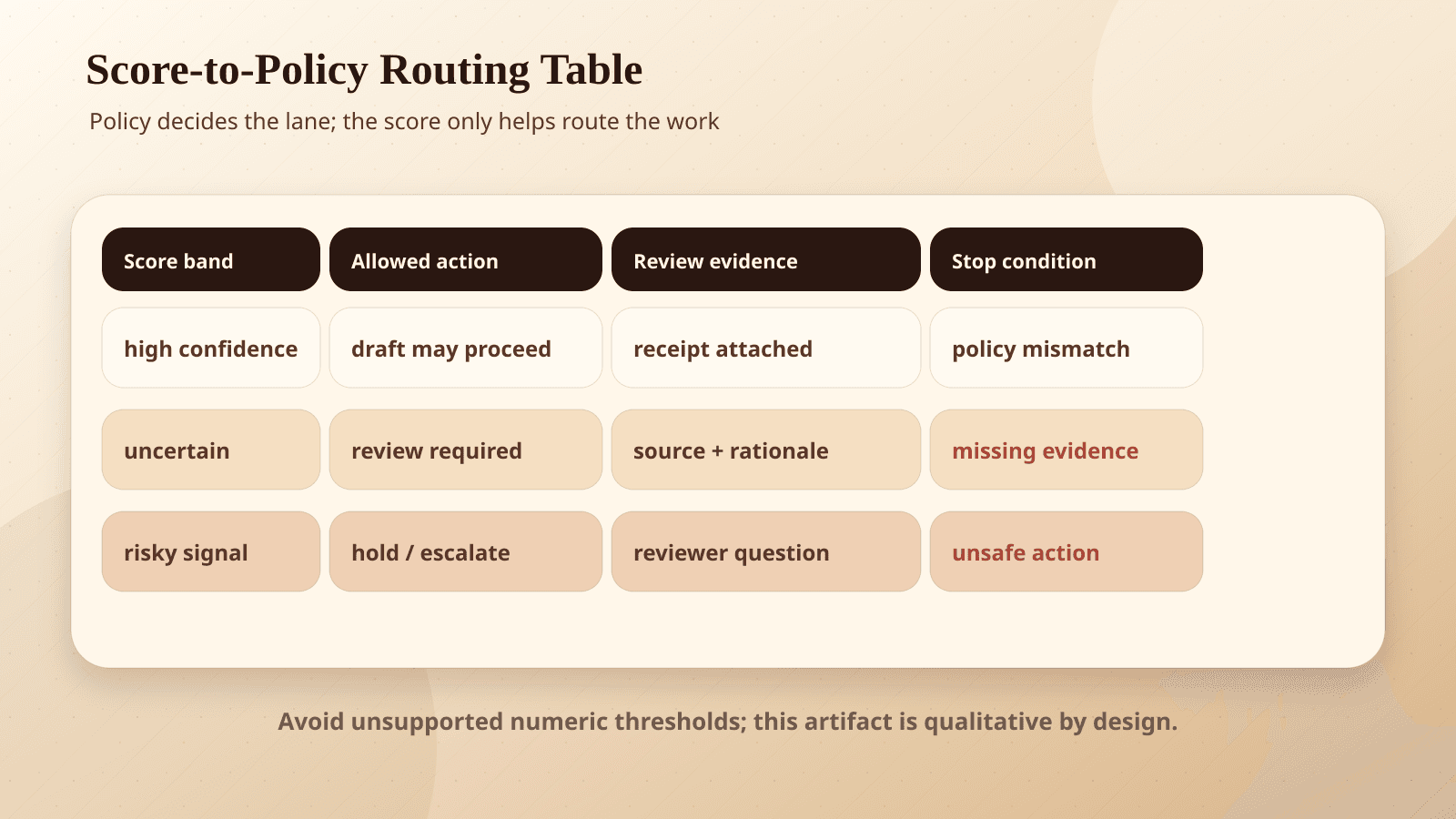
Add policy before automation
A practical AI approval policy should combine model signals with workflow facts.
For example:
- Auto-classify internal tickets when confidence is above 85% and the ticket does not mention legal, payment, account access, or security.
- Draft customer replies at any confidence level, but require human review before sending.
- Auto-approve data enrichment only for public fields and reversible updates.
- Escalate any request involving money, access, deletion, or regulated data regardless of confidence.
Notice the pattern. Confidence helps decide routing. Policy decides permission.
This is especially important for generative systems because the model may sound certain even when the underlying evidence is thin. A polished answer can make a weak decision feel stronger than it is.
Calibration is useful, not magic
Model calibration asks whether predicted confidence matches observed accuracy. If a well-calibrated model says 80% across many cases, roughly 80% of those predictions should be correct.
That is useful for planning. It helps teams estimate queue sizes, review load, and expected error rates.
But calibration is aggregate. Your business acts on individual cases.
A calibrated 90% bucket still contains failures. If those failures include refunds, account lockouts, medical advice, legal commitments, or public posts, the average does not protect you.
The question is not only, "How often is the model right?" It is, "What happens when it is wrong?"
Design queues by consequence
A better review design starts with consequence bands:
- Reversible and internal: allow more automation.
- Customer-visible but editable: draft automatically, review before send.
- Financial, access, legal, or safety impact: require approval regardless of score.
- Ambiguous or missing context: ask for more information before acting.
Then use confidence inside those bands.
A high-confidence, low-consequence item can move quickly. A low-confidence, low-consequence item can wait or be batched. A high-confidence, high-consequence item still needs a reviewer because the consequence is the point.
This keeps the model in its proper role. It informs the workflow controls. It does not govern the workflow by itself.
The plain-English test
Before using a confidence score to automate an action, ask three questions:
- If the model is wrong, who notices first?
- Can the action be reversed easily?
- Would we still require review if a junior employee made the same recommendation?
If the answers are uncomfortable, the threshold is not the problem. The policy is missing.
BaristaLabs tends to treat confidence as a routing hint, not a permission slip. That small framing change prevents a lot of expensive AI mistakes. It lets teams move faster where errors are cheap, and slow down where trust is on the line.
Implementation help
Turn confidence thresholds into reviewable workflow rules
BaristaLabs helps teams translate model scores into approval checkpoints, reviewer evidence, receipts, and escalation rules before production exposure.
Best fit when teams have model outputs or thresholds but not the operational rule that decides what can happen next.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.
Turn this idea into a pilot
Which workflow should go first?
Use the readiness check to compare impact, effort, risk, owner, and next step before booking a call.
- 3-5 minutes
- Deterministic score
- No sensitive data
Share this post