
At 3:18 p.m., two refund recommendations sat three rows apart in the same approval queue.
The first looked ordinary. The AI proposed a $42 credit for a customer who said a replacement shipment never arrived. The model score was high, the draft sounded careful, and the queue rule let it pass without finance review.
By 3:22, the customer had an email promising the credit. By 3:40, finance found the missing detail: the replacement had been delivered that morning and the account already had a courtesy credit from the prior ticket.
The second recommendation was cleaner. A $14 duplicate charge matched the payment record, the customer history was quiet, and the policy allowed automatic refunds under $25. The model hesitated. It sent the item to manual review, where it waited until the next morning.
Nobody outside the company saw that second mistake. The customer just waited. A reviewer eventually clicked approve after thirty seconds of checking.
Both were model errors. They did not feel the same.
The first error left the queue and created exposure. The second stayed inside the queue and created drag. That difference matters more to an operator than the vocabulary does.
The same queue can fail in two directions
Machine learning terms get easier when the queue has a visible job.
In this refund workflow, the positive class is "safe to approve automatically." Google's Machine Learning Crash Course describes a classification threshold as the probability cutoff that turns a model score into a positive or negative class.
Above the threshold, the model says yes. Below it, the item stays out of the positive class.
For the refund queue, yes means the proposed refund can leave review. No means the item waits for a person.
Now the two routed examples have names.
The $42 credit was a false positive: the model said "safe to approve" when the work was not safe. The $14 duplicate charge was a false negative: the model failed to recognize work that really was safe enough to approve.
The glossary is useful, but it is not the story. The story is where each mistake lands.
A false positive puts risk outside the queue. The customer sees a wrong promise. Finance cleans up the account. Support explains why the company sounded certain before it checked the record.
A false negative keeps cost inside the queue. Reviewers open a routine item, verify what the system should have recognized, and spend their attention on work that did not need judgment.
The first mistake feels like exposure. The second feels like friction.
False positives create outside exposure
A false positive in an approval queue is not just a bad label. It is an action that earned permission too early.
In a support queue, that action may be a refund email, a replacement order, an account status update, or a reply that promises a policy exception. In a content queue, it may be a page update that publishes before legal review. In a sales queue, it may be a CRM stage that triggers the wrong follow-up.
The queue looks efficient while the mistake is happening. Work moves. The backlog shrinks. The dashboard improves.
The cost appears somewhere else.
False positives often feel sharper than their count suggests. One bad auto-approval can create a customer-visible promise, a financial adjustment, a compliance concern, or a downstream record that other people now trust.
Google's lesson on accuracy, precision, and recall defines precision as true positives divided by everything the model classified as positive. In plain queue language: when the system lets work through, how often did it deserve to go?
High precision matters when the positive decision has consequences outside the review lane. It means fewer unsafe items get the fast path.
Low precision feels like a breach of permission. The team gave the system a lane for safe work, and the system used it for work that needed a person.
That is the emotional difference. False positives make the business ask, "What did we just let happen?"
False negatives create inside drag
A false negative has a quieter signature.
The AI does not approve the clean $14 refund. It does not send the obvious password-reset ticket to the right response lane. It does not recognize that a low-risk internal tag can move without a manager.
The work waits.
Reviewers absorb the mistake as extra clicks, extra context switching, and extra doubt. The customer may experience delay, but the business usually feels the pain first as queue drag.
Google defines recall as true positives divided by all actual positives. In queue language: of the work that really could have moved safely, how much did the model catch?
Low recall creates a strange kind of disappointment. The system may be safe, but it is not useful enough. Reviewers keep finding obvious cases in the manual pile and start wondering why the AI is there at all.
That can push teams toward a dangerous overcorrection. They lower the threshold until more items move. Recall improves because fewer safe cases get trapped. Precision may fall because more borderline cases now leave the queue.
The threshold tuning article covers that slider problem in detail. False negatives are not harmless just because they stay internal.
They spend reviewer time. They slow customer answers. They train people to ignore the queue's recommendations because the system is too timid to be operationally useful.
A false negative makes the business ask, "Why are people still doing the easy work by hand?"
Draw the two routed examples
Before changing a score, draw one false positive and one false negative from the same workflow.
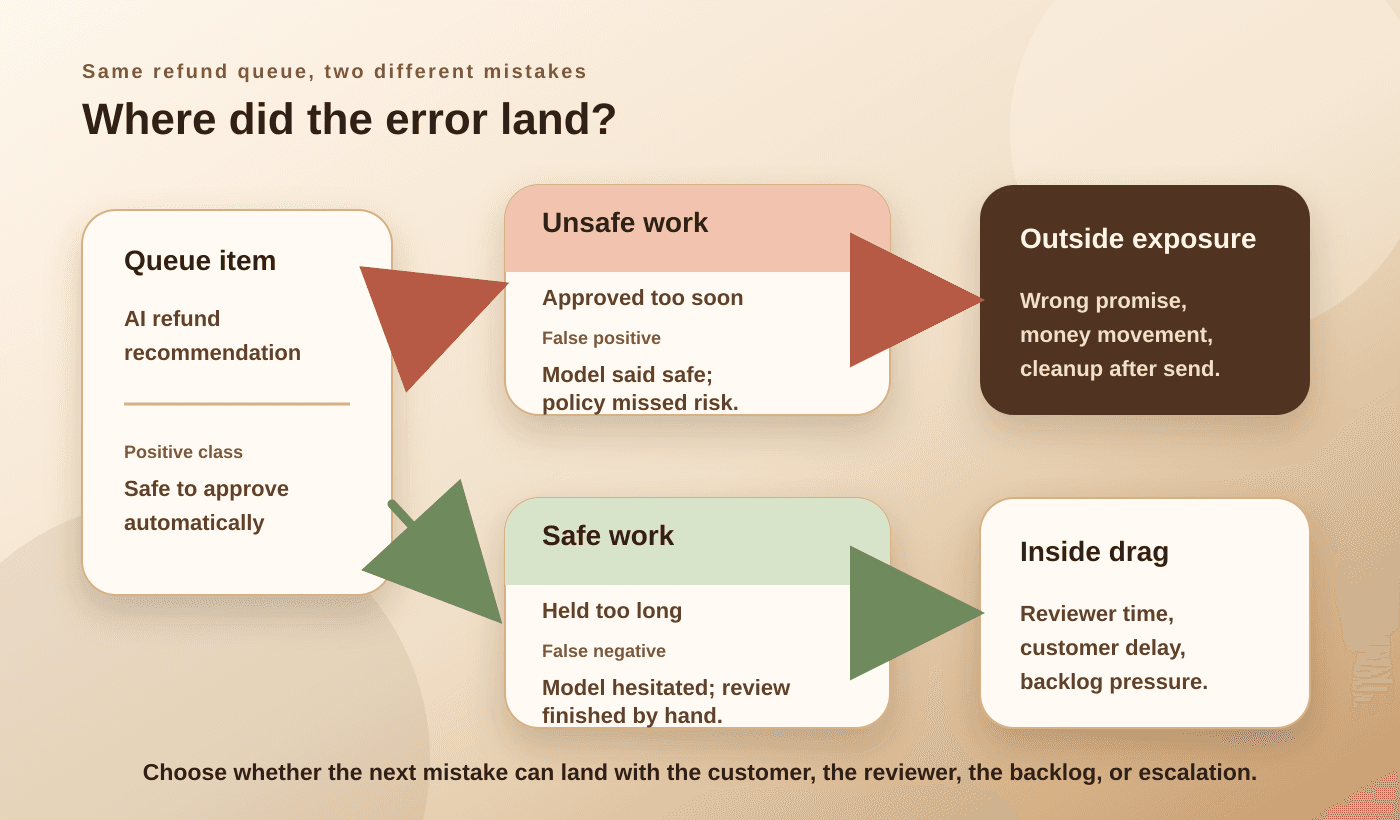
Use the same positive class for both. In the refund queue, positive means safe to approve automatically.
False positive: unsafe refund approved too soon
Consequence: money, promise, or system-of-record update leaves the queue before review
False negative: safe refund held too long
Consequence: reviewer time and customer delay stay inside the queue
This small drawing prevents a common meeting failure. Teams talk about false positives and false negatives as if they are symmetric boxes in a model report. They are not symmetric to the people running the workflow.
One error has an outside address. The other has an inside address.
The addresses can change if you define the positive class differently. If positive means "risky enough to review," a false positive becomes unnecessary review load and a false negative becomes missed risk. The vocabulary flips because the queue's target changed.
The approval queue design should name the proposed action, the policy rule, the reviewer decision, and the receipt. The team needs to know what the model is trying to route before the metrics mean anything.
Field note: do not argue about the metric before naming the action
Ask one sentence first: "What does a positive decision allow the workflow to do?"
If the answer is "send money," "email the customer," "change the record," or "publish the page," false positives deserve special attention. If the answer is "send to review," false negatives may be the dangerous missed-risk bucket instead.
The business tolerance is not one number
Scikit-learn's guide to decision threshold tuning separates two jobs: estimating probabilities and deciding what action to take from those probabilities.
That split is the heart of approval-queue design.
The model can estimate that a refund recommendation looks safe. The workflow still has to decide whether that estimate is enough to approve the refund, ask finance, request more evidence, or keep the action manual.
A 92% score should not mean the same thing everywhere.
A reversible internal tag may tolerate more false positives because the cleanup cost is low. A customer-facing refund promise may require very high precision. A security escalation lane may tolerate more false positives because missing a real account-takeover signal is worse than asking a specialist to inspect a few extra tickets.
The team should not ask, "Which mistake is bad?" Both are bad. Ask which mistake the workflow can absorb.
Can the customer absorb it? Can a reviewer absorb it? Can the backlog absorb it? Can an escalation lane absorb it? Can the business explain it later from the receipt?
If the answer is no, the action should not skip review yet.
Receipts make the mistake reviewable
A queue without receipts turns false positives and false negatives into anecdotes.
Someone remembers the $42 refund that slipped through. Someone else remembers the morning spent approving obvious $14 refunds. The conversation becomes a contest between fear and frustration.
The agent receipt template gives the team a better artifact. It should show the input, source evidence, model signal, policy rule, reviewer action, final output, timestamp, and rollback path.
For the false positive, the receipt should answer:
What source field made the model think the refund was safe?
Which policy rule allowed the item to bypass review?
What evidence was missing or stale?
Who, if anyone, could have stopped it?
What customer or system record changed?
For the false negative, the receipt should answer:
Which safe condition did the model fail to recognize?
What evidence did the reviewer use to approve it quickly?
How many similar items are waiting in the queue?
Can this become a narrower fast lane?
The second set matters. Teams often inspect the dramatic miss and ignore the boring drag. That leaves the workflow safe but underpowered.
A useful review samples both piles: items approved too soon and items held too long.
Tune the lane, not the mood
The worst time to move a threshold is right after one memorable mistake.
A false positive makes everyone want to tighten the queue. A stack of false negatives makes everyone want to loosen it. Both reactions are understandable. Neither is enough.
Tune the lane after the team can describe the error pattern.
If risky refunds are slipping through because cancellation language is missing from the policy rule, add a blocker. If clean duplicate charges under $25 keep waiting because the payment record is formatted differently, fix the source or create a narrow fast lane. If reviewers keep opening other systems to understand the recommendation, improve the evidence packet before touching the threshold.
A confidence score is not an approval policy. A score can help rank or route work. It cannot decide what the business is allowed to automate.
A good approval policy names the action, the evidence required, the score range, the exceptions, the owner, the receipt, and the rollback path. The score is only one part of that policy.
Choose where the next mistake should land
False positives and false negatives are useful terms because they force a team to name two different mistakes.
They are not useful if the conversation stops at the terms.
In a refund approval queue, a false positive can put a wrong promise in front of a customer. A false negative can put a safe refund in front of a reviewer who should not have needed to touch it. One error spends trust outside the queue. The other spends time inside it.
The implementation decision is not abstract: choose where the next mistake should land.
If the next mistake cannot reach the customer, tighten the auto-approval lane, add blockers, or keep the action manual. If the next mistake can safely stay inside the queue while the team learns, make that explicit and watch the review load. If the queue is drowning in safe work, carve out a narrow lane instead of loosening every rule.
BaristaLabs helps teams turn that decision into an approval queue: proposed action, source evidence, policy rule, threshold, reviewer packet, and receipt. Start with two examples from the same workflow. One that left too soon. One that waited too long. Then design the lane around the mistake the business can actually tolerate.
Implementation help
Route the next mistake on purpose
BaristaLabs helps teams connect false positives, false negatives, review load, approval policy, and receipts before AI starts touching customer work.
Best fit when a workflow already has scores or AI drafts, but the team is still deciding which mistakes can be tolerated and which must be trapped.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.
Turn this idea into a pilot
Which workflow should go first?
Use the readiness check to compare impact, effort, risk, owner, and next step before booking a call.
- 3-5 minutes
- Deterministic score
- No sensitive data
Share this post