pip install unsloth && unsloth studio setup && unsloth studio — three commands, and you have a browser-based training UI on localhost. Every tweet from launch day leads with the same number: 2x faster training, 70% less VRAM. That's real. It's also the least interesting thing Unsloth Studio shipped.
The dataset bottleneck had no UI until now
Fine-tuning a model in 2026 is a solved problem at the mechanical level. LoRA adapters, QLoRA, FP8 quantization, PEFT — the training toolchain has been commoditized for over a year. What actually kills most fine-tuning projects is the step before training: building the dataset.
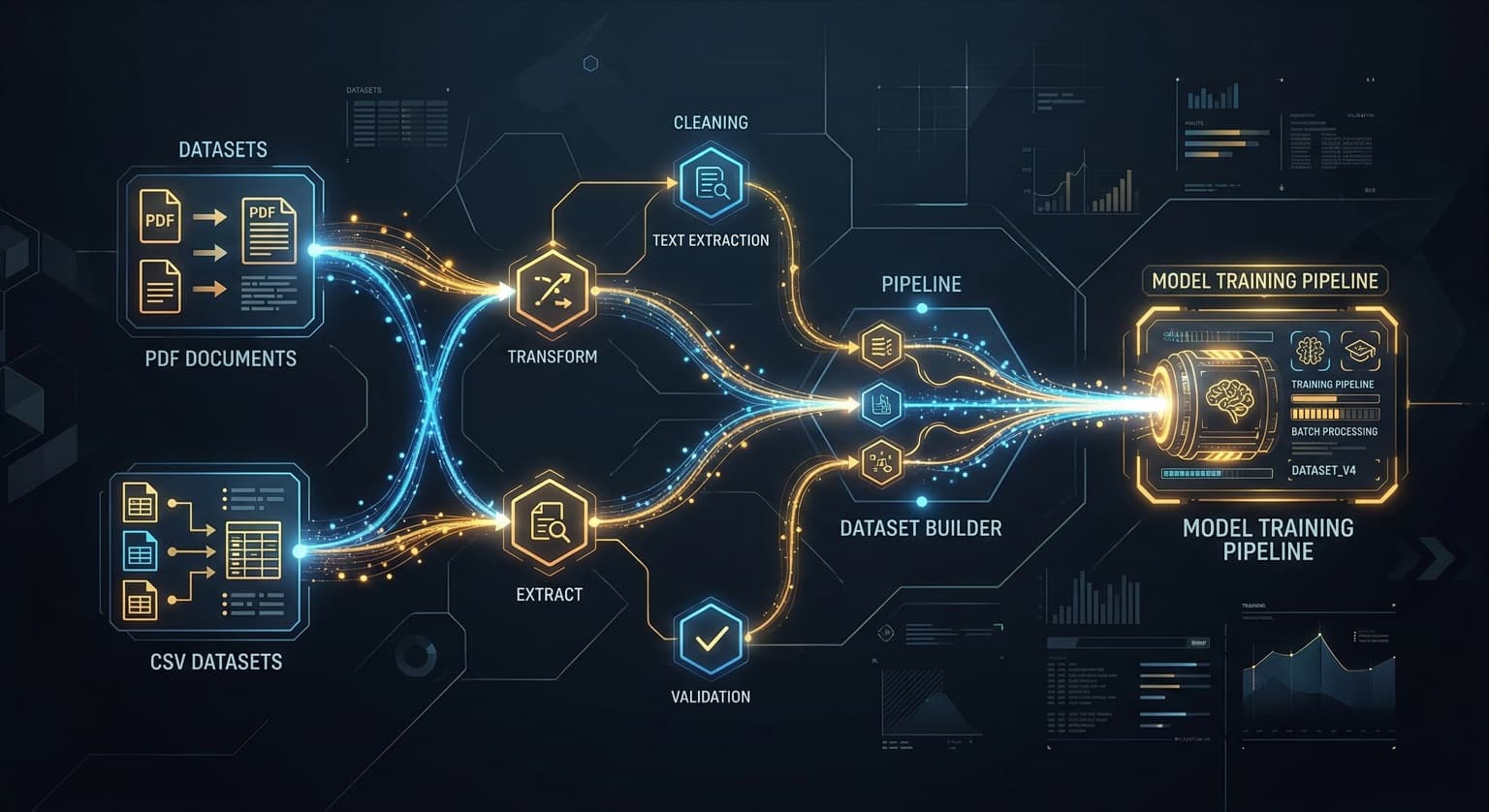
You have a pile of company PDFs, a CSV export from your CRM, maybe a DOCX style guide. Turning that into supervised pairs — instruction, response, validation — has meant Jupyter notebooks, manual labeling, or paying a data vendor. Unsloth Studio ships a feature called Data Recipes that takes a direct run at this problem.
Data Recipes is a visual node-graph editor. You upload unstructured or structured files (PDF, CSV, JSON, DOCX, TXT), then wire together processing blocks on a canvas: seed data nodes, LLM generation blocks, Jinja2 expression transforms, deterministic samplers for category columns, and code validators with built-in linters for Python, SQL, and JavaScript. The system chunks your documents into rows, runs them through generation pipelines, and outputs a training-ready dataset. Preview a sample before committing to the full build.
Under the hood, Data Recipes runs on NVIDIA's DataDesigner — the same synthetic data framework NeMo teams use internally. Unsloth wraps it in a drag-and-drop interface and stores recipes locally in the browser, exportable and shareable between users.
What "Mac, Windows, Linux" actually means on the install page
Unsloth Studio's marketing lists all three operating systems. The fine print splits them into two tiers.
Inference only: macOS (Intel and Apple Silicon), any CPU-only machine. You can chat with GGUF and safetensor models, use the model arena to compare outputs, and run self-healing tool calls. MLX-based training on Apple Silicon is listed as "coming soon" with no date.
Full training: NVIDIA GPUs — RTX 30-series through 50-series, Blackwell, DGX Spark, DGX Station. Multi-GPU training works today with a "major upgrade on the way."
If you're evaluating Unsloth Studio on a MacBook to decide whether to spin up a GPU instance for training, the inference and data-prep workflow runs locally. The actual training step requires NVIDIA hardware. That's a reasonable split, but you have to read the docs to find it — the landing page buries the distinction.
Self-healing tool calls change the fine-tuning feedback loop
Models running inside Unsloth Studio get a feature called self-healing tool calling: if the model generates a malformed function call, the system automatically retries with corrected schema. Add code execution — the model can run Python and verify its own outputs — and you get a tighter validation loop without leaving the UI.
The Model Arena feature ties this together for fine-tuning evaluation. Load a base model and your newly trained adapter side by side, send identical prompts, and compare outputs in split view. For anyone doing iterative fine-tuning (train, evaluate, adjust data, retrain), collapsing evaluate-and-compare into the same interface where you built the dataset removes a context switch that used to cost a full afternoon of notebook wrangling.
One cost line for the agency owner quoting a custom model project
A two-person agency quoting a client $5,000–$8,000 for a "custom AI model" — say, a fine-tuned product description generator for an e-commerce catalog — typically spends 60–70% of that budget on data preparation. Cleaning CSVs in pandas, writing prompt templates, manually reviewing output samples, iterating.
Data Recipes compresses that into a visual pipeline that previews before it builds. The training itself was already the cheap part — a 7B LoRA fine-tune on an RTX 4090 finishes in under an hour. If data prep drops from 20 hours to 4 hours for a typical small-catalog project, the margin on that $5K engagement shifts from breakeven to profitable.
Unsloth Studio is open source under the standard Unsloth license, installs via pip, and runs entirely offline. The speed numbers are real. The dataset tooling is the part that changes who can actually ship a fine-tuned model.
Turn this idea into a pilot
Which workflow should go first?
Use the readiness check to compare impact, effort, risk, owner, and next step before booking a call.
- 3-5 minutes
- Deterministic score
- No sensitive data
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.