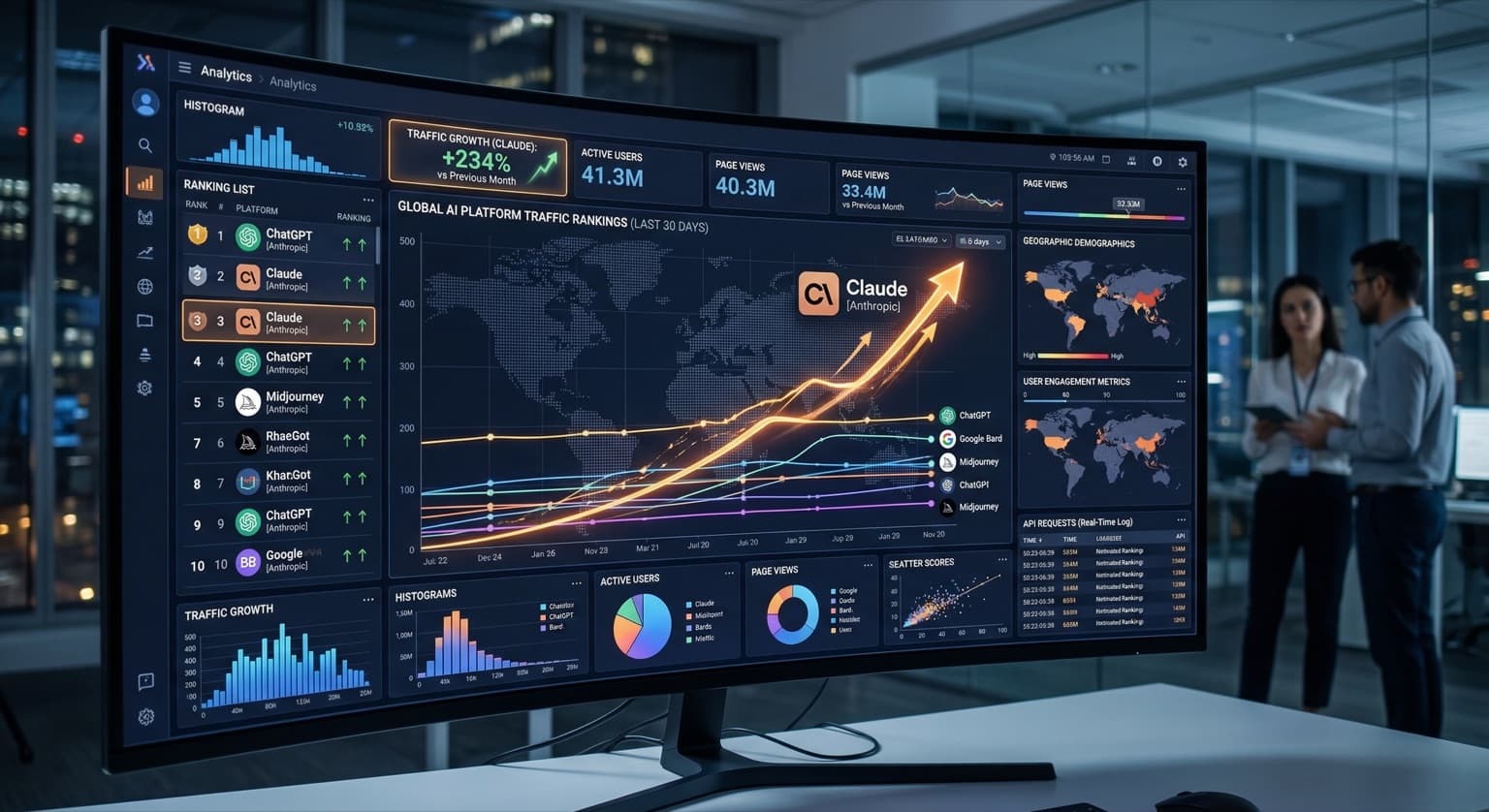
Anthropic's Claude saw a 61% jump in web traffic during February 2026. That is one of the largest single-month increases any major AI platform has recorded — and almost nobody covered it.
The same month, the AI press was saturated with benchmark comparisons. Who scored highest on MMLU. Which model edged ahead on HumanEval. Whether the latest release moved the needle on reasoning tasks by two percentage points.
Meanwhile, tens of millions of new users were quietly voting with their keyboards.
Benchmarks measure capability. Traffic measures trust.
There is a growing disconnect between how AI companies market their models and how real people choose which tools to use. Benchmarks tell you what a model can do in controlled conditions. Traffic tells you what people actually rely on.
Claude's February surge did not coincide with a new model release or a viral marketing campaign. It coincided with something harder to manufacture: word of mouth. People telling colleagues that Claude handled a complex document better than expected. Teams discovering that the conversation style fit their workflow. Developers finding the API reliable enough to build on.
None of that shows up on a leaderboard.
Why this matters if you run a small business
If you are evaluating AI tools for your business, the benchmark fixation can actively mislead you. A model that scores three points higher on a coding benchmark might be worse at the specific task you need — summarizing customer emails, drafting proposals, or answering product questions.
Here is what to pay attention to instead:
Usage growth over time. A platform gaining millions of users monthly is a platform people keep coming back to. Retention is harder to fake than a benchmark score.
Reliability at your use case. The best AI tool for your business is the one that handles your tasks well, not the one that tops a leaderboard designed by researchers.
Integration and workflow fit. Claude's growth partly reflects that Anthropic invested in making the product usable — better document handling, longer context windows, and an interface that does not fight you. For a small business, ease of use matters more than raw capability.
Community and ecosystem. Tools with growing user bases attract more integrations, more tutorials, and more support resources. That momentum compounds.
The benchmark trap
The AI industry has a benchmarking problem. New models launch with elaborate comparisons against predecessors, always showing improvement on carefully selected metrics. But the benchmarks themselves are starting to saturate — differences of one or two points at the top of a leaderboard are statistically meaningless for practical applications.
Worse, optimizing for benchmarks can actively hurt real-world performance. A model tuned to ace a specific test format might struggle with the messy, ambiguous requests that make up actual business use. The map is not the territory.
When Anthropic's traffic numbers tell a different story than the benchmark rankings, that gap deserves attention.
What to do with this information
If you are already using an AI tool and it works for your needs, do not switch because a competitor posted better benchmark numbers. Switching costs are real, and a two-point improvement on a standardized test will not offset the disruption of changing your workflow.
If you are shopping for an AI tool, try the actual tasks you need done. Give each platform the same five real requests from your business — not toy examples, but the messy stuff you deal with daily. Judge the results yourself.
And pay attention to where the users are going. Sixty-one percent growth in a single month is a signal. Not the only signal, but one worth weighing alongside the spec sheets.
The AI industry wants you to evaluate tools the way they market them — on paper, in controlled comparisons, with numbers that favor the latest release. Your business deserves a more practical approach.
AI Pilot Readiness Checklist
Turn the idea into a pilot you can defend.
AI agent articles are easy to bookmark and hard to operationalize. Use the readiness questions as a shared way to decide whether a workflow is specific enough, safe enough, and measurable enough to pilot. If they surface a strong candidate, BaristaLabs can review it with you and help shape a first version that fits your systems, approval process, and risk tolerance.
Please do not submit PHI, customer records, credentials, or confidential workflow exports.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.