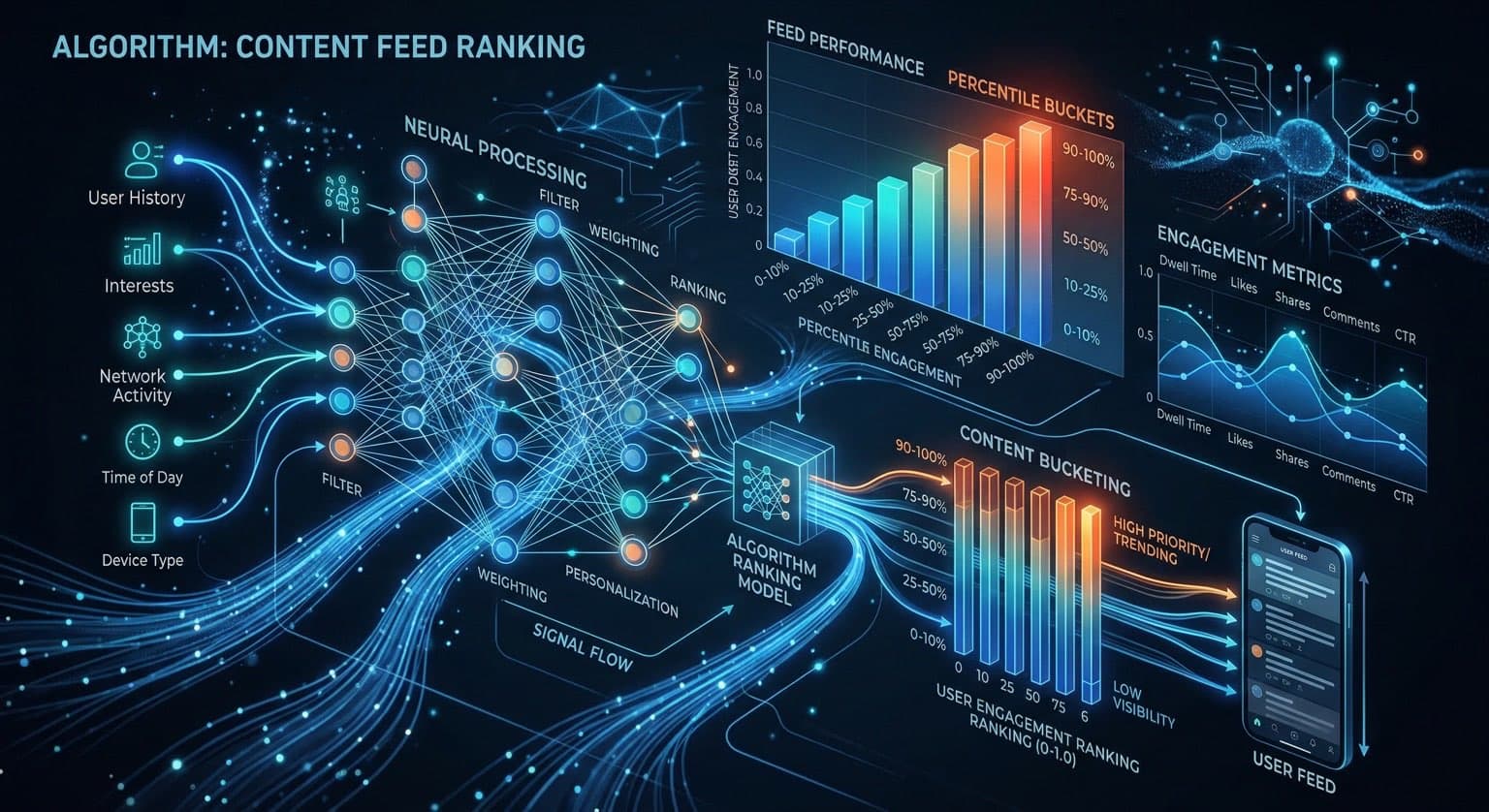
LinkedIn says its new feed now serves more than 1.3 billion professionals and uses an LLM-plus-GPU ranking stack, but the most practical line in the engineering post was this one: turning raw engagement counts into percentile buckets improved retrieval recall@10 by 15%.
That matters more than the headline if you run content for a 20-to-50 person firm with a stack like LinkedIn, HubSpot, Clay, and Taplio. An agency owner or in-house ops lead can spend $1,500 to $3,000 a month on AI-assisted content production and scheduling, then still miss distribution because the system cannot cleanly interpret weak, noisy signals. LinkedIn’s own writeup is a reminder that better formatting of signals can beat another layer of generic content generation.
The 15% lift came from formatting, not a bigger model
In LinkedIn’s engineering post, the team explains that raw numbers performed badly inside prompt text. A post with 12,345 views initially showed up as a token string like views:12345, which gave them a near-zero correlation of -0.004 between popularity counts and cosine similarity in retrieval.
Their fix was aggressively unglamorous. Instead of passing the raw number, they converted it into percentile buckets wrapped in special tokens, so the same signal became something like <view_percentile>71</view_percentile>. After that change, LinkedIn says the correlation between popularity features and embedding similarity jumped 30x, and recall@10 improved by 15%.
That is the buried detail worth stealing. The gain did not come from a splashier model announcement. It came from making messy operational data legible to the model.
The expensive mistake hiding in most AI content workflows
A lot of AI content systems for B2B teams still treat performance data like decoration. They dump raw impressions, clicks, likes, or watch time into dashboards, prompts, or enrichment layers and assume the model will infer magnitude correctly.
LinkedIn is saying, pretty plainly, that this is naive.
LLMs do not naturally understand that 12,345 is materially different from 1,234 in a way that maps cleanly onto ranking usefulness. Tokenization gets in the way. Ordinal meaning gets lost. The model sees text, not business significance.
For an operator running a repurposing machine, that has a direct cost. If your team publishes 12 LinkedIn posts a month and pays one strategist plus one AI toolchain to turn founder notes, webinar clips, and customer stories into content, even a 25% miss rate on distribution quality can burn $800 to $1,200 a month in wasted production time before you count opportunity cost.
The practical read is blunt: before you buy more writing automation, tighten the way your workflow packages performance signals. Bucket ranges. Normalize recency. Separate quality signals from vanity noise. If LinkedIn needed that discipline for its own feed, your internal content ops definitely do.
LinkedIn also cut compute by learning from positives only
The second undercovered detail is not about ranking quality. It is about system cost.
LinkedIn says it originally trained retrieval on all impressed posts, including content members ignored. That hurt performance and made training more expensive because GPU compute rose with sequence length. When the team filtered interaction history down to positive engagements only, it reported a 37% reduction in per-sequence memory footprint, capacity for 40% more training sequences per batch, and 2.6x faster training iterations on an 8x H100 setup.
That should ring loud for any IT buyer evaluating AI tooling inside a small or midsize company. Bigger context windows sound impressive in demos, but indiscriminate history can make systems slower, pricier, and worse. More context is not automatically more intelligence. Sometimes it is just more junk for the GPU bill.
The operator lesson is simple: if you are building an internal recommendation, lead-scoring, or content-ranking workflow, document what counts as a positive event before you scale data collection. In a real stack that might mean HubSpot lifecycle changes, qualified demo requests, booked calls, or meaningful saves—not every pageview, scroll, or stray reaction.
This changes how to test LinkedIn content from here
The usual advice after a feed update is to post more, comment faster, and chase formatting tricks until something sticks. LinkedIn’s own engineering notes point in the opposite direction.
Its system is getting better at semantic matching, cold-start inference from profile data, and near-real-time updates. But the stronger signal in the writeup is that infrastructure quality still decides who benefits. Better signal encoding, better negative sampling, and cleaner engagement history are doing real work behind the scenes.
So if you manage LinkedIn as a demand channel, stop treating the platform as a copywriting contest. Treat it like a ranking system that rewards clean inputs. Keep the AI writing layer if it helps throughput, but test a stricter workflow around structured post topics, normalized engagement bands, and explicit definitions of success.
Verdict: test signal cleanup before you buy another content bot.
AI Pilot Readiness Checklist
Turn the idea into a pilot you can defend.
AI agent articles are easy to bookmark and hard to operationalize. Use the readiness questions as a shared way to decide whether a workflow is specific enough, safe enough, and measurable enough to pilot. If they surface a strong candidate, BaristaLabs can review it with you and help shape a first version that fits your systems, approval process, and risk tolerance.
Please do not submit PHI, customer records, credentials, or confidential workflow exports.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.