OpenAI released GPT-5.4 this week and most coverage landed on the same headline: it's faster, smarter, consolidates Codex. True, all of it. But the coverage buried the number that actually changes how you should think about deploying agents in a production workflow.
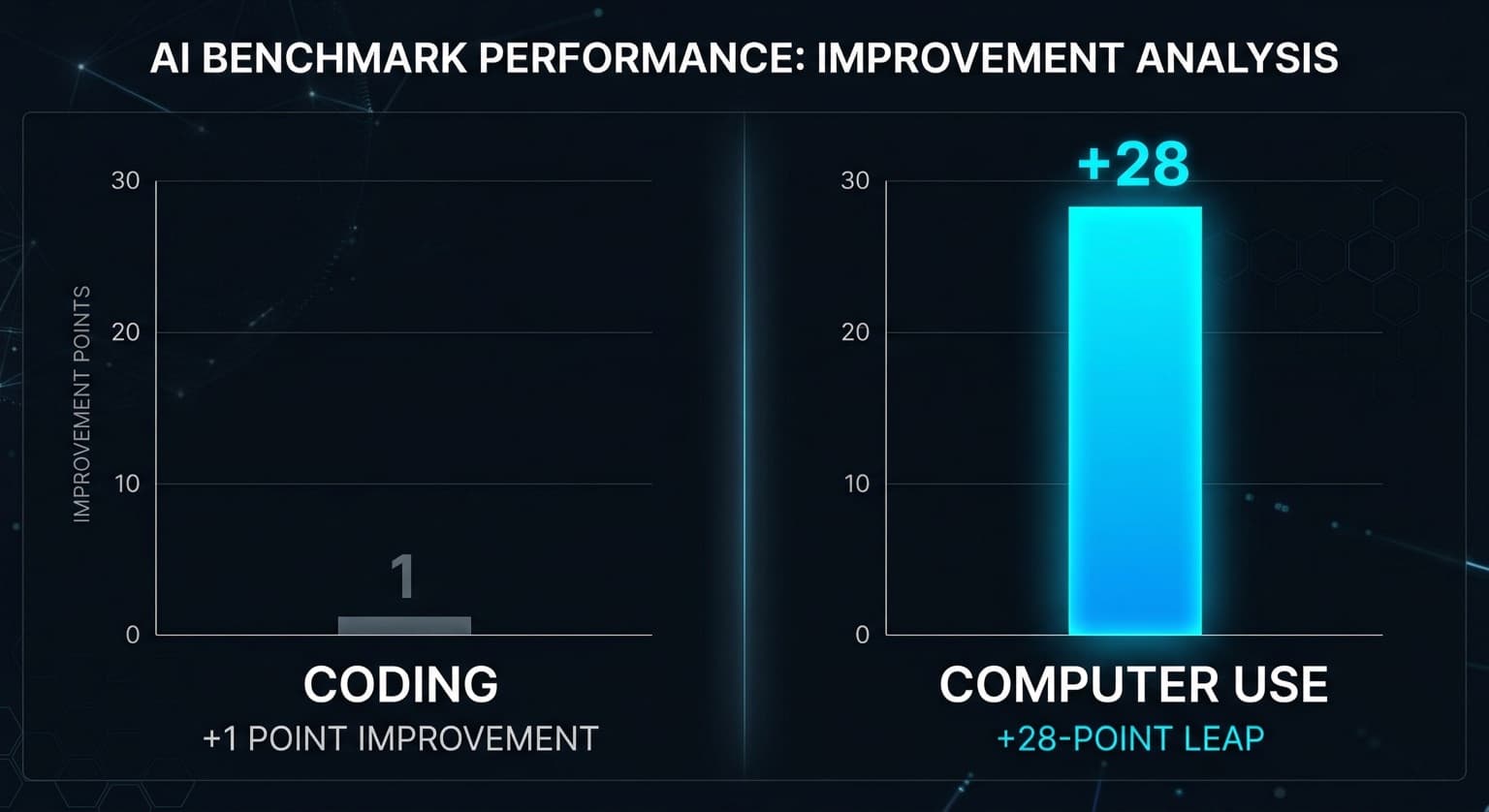
On SWE-Bench Pro (coding), GPT-5.4 scored 57.7%. GPT-5.3-Codex scored 56.8%. That's a 0.9-point improvement on the benchmark that dominated AI coding discourse for two years. On OSWorld-Verified (computer use — navigate apps, fill forms, operate browsers autonomously), GPT-5.4 scored 75.0%. GPT-5.2, its predecessor, scored 47.3%. That's a 27.7-point jump.
These two numbers are not telling the same story.
The Benchmark Nobody Led With
OSWorld measures something fundamentally different from coding. It doesn't ask a model to generate a diff. It asks a model to navigate a live desktop application environment: open a spreadsheet, find a specific cell, enter a value, export the file, attach it to an email. Tasks that a human employee would describe as administrative overhead, not skilled work.
The 47.3% score on GPT-5.2 meant autonomous computer use was interesting but unreliable in production. One in two tasks would fail or require intervention. At 75.0%, you're in a different regime. Three in four tasks complete correctly without a human in the loop. That's the threshold where you can start building workflows around the capability rather than around its failure modes.
For context: GPT-5.3-Codex, which OpenAI specifically positioned as its agentic coding model, scored 74.0% on OSWorld when measured with a newly introduced API parameter that preserves original image resolution. GPT-5.4 matched it as a general-purpose model — the same model handling your prose, your spreadsheet, and your browser automation.
One Model Where OpenAI Used to Ship Three
The consolidation angle isn't trivial. Until GPT-5.4, a developer building an agentic workflow that needed reasoning, coding assistance, and computer-use interaction had to either: (a) route requests across multiple model endpoints with different pricing tiers, context limits, and API surfaces, or (b) accept degraded performance by forcing one model to do work it wasn't optimized for.
GPT-5.4 has native computer-use capabilities built into the same endpoint handling your reasoning and coding tasks. It also supports up to 1M tokens of context, which matters for long-horizon agents that need to plan, execute, verify, and revise across an extended sequence of tool calls.
The operational simplification is real: one API key, one token budget, one model to version-pin in your config. The productivity win from fewer moving parts in your integration layer compounds over time, especially for small dev teams maintaining more than they built.
What the GDPval Number Means for Knowledge Workers
OpenAI also published results on GDPval, a benchmark that tests agents against 44 professional occupations on real knowledge work tasks — the kind of deliverables a human professional would produce in a billable hour. GPT-5.4 matched or exceeded industry professionals in 83.0% of comparisons. GPT-5.2 was at 70.9%.
That's a 12-point improvement in one generation on a benchmark that's closer to "does this output pass QA?" than "can it solve an algorithm puzzle." For a marketing ops lead, a solo consultant, or a 25-person professional services firm, the relevant question isn't whether GPT-5.4 is smarter in the abstract. It's whether the output from an agent running GPT-5.4 clears your internal review bar without rework. At 83%, you're approaching a ratio where the exception handling is manageable rather than dominant.
Before and After for the Agency Running Document Workflows
Consider a 15-person digital agency producing client-facing deliverables: monthly performance reports, proposal decks, campaign summaries. Previously, an AI-assisted workflow looked like: prompt → draft → human edits → format in Google Slides → export → send. The model handled generation, humans handled everything downstream.
With GPT-5.4's computer-use capabilities, an agent can generate the content and operate the presentation software: open the template, populate each slide, export the PDF, and drop it into the shared client folder — without a human touching the keyboard for the last three steps. That's not a speculative use case. OSWorld-Verified tests exactly those kinds of multi-step application workflows, and GPT-5.4 completes them at 75%.
The token efficiency improvement matters here too. OpenAI states GPT-5.4 uses significantly fewer tokens than GPT-5.2 to solve problems. For an agency running dozens of these workflows per week across multiple client accounts, that reduction translates directly into API cost, not just latency.
The coding story for GPT-5.4 is incremental. The computer-use story is a step change. Workflows that required a human hand-off in the middle — because no model could reliably operate software autonomously — just got a new ceiling. If your team's current AI integration stops at text generation and hands off to a human for everything that requires clicking, that hand-off is now optional on three out of four tasks.
AI Pilot Readiness Checklist
Turn the idea into a pilot you can defend.
AI agent articles are easy to bookmark and hard to operationalize. Use the readiness questions as a shared way to decide whether a workflow is specific enough, safe enough, and measurable enough to pilot. If they surface a strong candidate, BaristaLabs can review it with you and help shape a first version that fits your systems, approval process, and risk tolerance.
Please do not submit PHI, customer records, credentials, or confidential workflow exports.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.