InsForge 2.0 is interesting for one reason: it stops pretending a coding agent can build a production backend from vibes alone.
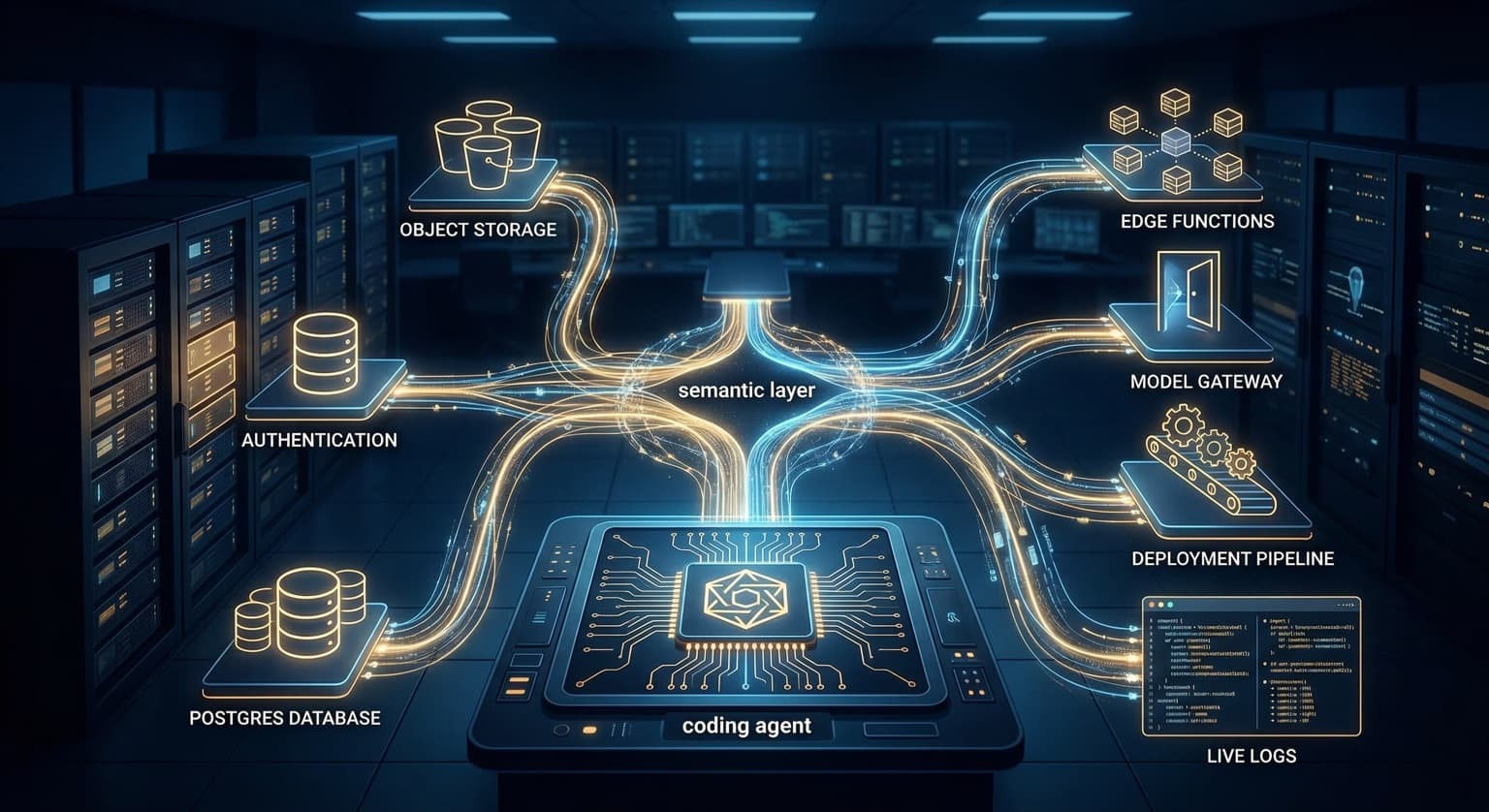
Most launch chatter framed InsForge as another “agentic development” product. The more important detail lives in the company’s own docs and GitHub repo: InsForge exposes backend primitives through a semantic layer that agents can fetch, configure, and inspect directly. That means authentication, Postgres, storage, edge functions, model routing, deployment state, and logs are being turned into machine-readable operating context instead of remaining a pile of dashboards, CLI commands, and half-remembered setup steps.
That is a much bigger deal than the branding.
The buried detail in the launch
InsForge’s README describes the product as a backend platform for AI coding agents, but the differentiator is narrower and more practical than that. Its semantic layer is designed to let an agent do three specific things: fetch backend documentation, configure backend primitives, and inspect backend state through structured schemas.
That last part is the one most coverage will glide past. Plenty of tools help a model generate code. Fewer give the model a reliable way to inspect the live state of the system it is changing. When a platform exposes state and logs in structured form, the agent is no longer guessing whether auth is broken, whether a storage bucket exists, or whether a function deployment actually succeeded.
InsForge is also bundling more surface area than the average “AI backend” tool. The public repo and product materials point to authentication, database, storage, edge functions, a model gateway, and site deployment in the same operating layer. In plain English: the product is trying to collapse the handoff points where coding agents usually fall apart.
Where the current workflow usually breaks
A solo developer using Cursor, Claude Code, or another code editor agent can already scaffold a front end fast. The drag starts the moment the app needs real backend plumbing.
The normal workflow still looks annoyingly manual:
- create a Postgres instance
- wire authentication rules
- provision object storage
- deploy serverless functions
- copy environment variables
- switch between docs, dashboards, terminals, and logs
- feed all of that back into the coding agent when it gets lost
That context-switching tax is the real cost center. It is not just slow. It also creates brittle output, because the agent is always one stale prompt away from hallucinating the backend state.
InsForge’s bet is that if the platform itself becomes the context layer, the model no longer has to reconstruct reality from screenshots and pasted config blocks. For a 20-to-50-person product team with one overstretched ops lead, that could cut initial internal-tool setup from roughly 3 to 5 hours down to about 45 to 90 minutes on a straightforward CRUD app with auth, uploads, and one scheduled function. That estimate is not magic; it is what happens when you remove repeated dashboard hopping, config translation, and “wait, what environment are we in?” cleanup.
A realistic build path for one operator
Take a solo dev at a small agency building a client portal. The deliverable is simple on paper: client login, project files, a messaging thread, a usage dashboard, and an AI-assisted content brief generator.
Without a platform like this, the operator is probably mixing Supabase or Firebase, a storage layer, Vercel or Cloudflare functions, one or two model APIs, and a long prompt telling the coding agent how the pieces fit. That can work, but it turns every edit into a context-management problem.
With InsForge’s approach, the operator can hand the agent a backend that already exposes its moving parts in a way the agent can interrogate directly. The practical stack becomes clearer:
- auth and sessions inside InsForge
- Postgres for relational data
- S3-compatible storage for client files
- edge functions for webhook or scheduled logic
- model gateway for routing prompts across providers
- deployment hooks from the same platform layer
That is the first setup in this category that feels realistic for an operator who wants one prompt to become a full stack build path instead of a front-end mockup with backend chores still waiting.
The risk is vendor concentration, not model quality
There is still a catch, and it is the one buyers should document before they get excited.
InsForge is reducing operational sprawl by pulling a lot of primitives into one layer. That improves agent reliability, but it also concentrates blast radius. If auth, database operations, storage access, model routing, and deployment visibility all sit behind the same semantic layer, then a platform outage, pricing change, or security incident does not just slow one feature down. It can stall the whole app factory.
That makes the vendor-risk checklist obvious:
- export path for data and storage assets
- fallback plan for model gateway routing
- backup path for auth and session logic
- local or self-hosted deployment option
- logging access outside the platform UI
To InsForge’s credit, the company is at least signaling portability. The open-source repo is Apache 2.0 licensed, local deployment is documented with Docker, and the default local instance runs on port 7130. Those details matter because they turn “platform dependence” into “platform dependence with an escape hatch,” which is a much healthier category.
The editorial call is simple: InsForge 2.0 is not important because it says the word agent more loudly than everyone else. It is important because it is trying to make backend reality legible to the agent in the first place.
AI Pilot Readiness Checklist
Turn the idea into a pilot you can defend.
AI agent articles are easy to bookmark and hard to operationalize. Use the readiness questions as a shared way to decide whether a workflow is specific enough, safe enough, and measurable enough to pilot. If they surface a strong candidate, BaristaLabs can review it with you and help shape a first version that fits your systems, approval process, and risk tolerance.
Please do not submit PHI, customer records, credentials, or confidential workflow exports.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.