
The operations lead wires the fourth integration into the agent on a Tuesday. Calendar, the CRM, a billing endpoint, internal doc search. The agent answers questions, drafts the right emails, and pulls the right records. For one afternoon, the integration list looks like leverage.
By the fourteenth integration, something has quietly shifted. Every request now opens with a wall of tool descriptions the model has to read before it does any work. The agent is still correct, mostly, but it is slower, and the bill is climbing for reasons nobody can point at on a chart.
By the fortieth, the context window is a junk drawer. Forty tool schemas load on every single turn, including the thirty-seven that have nothing to do with the question being asked. The agent occasionally picks the billing tool when it wanted the invoicing one, because both descriptions are sitting in the prompt looking equally plausible. The ops lead is now spending Friday afternoons trimming tool descriptions to win back tokens. That is not the job they signed up for.
This is the failure mode nobody warns you about when you start connecting agents to things. It is not that the tools do not work. It is that you loaded all of them, all the time, before the agent knew which one it needed.
The shape of the problem: a toolbelt that never comes off
The way most teams connect agents today is install-first, use-later. You decide ahead of time which capabilities the agent might need, you hardcode the MCP server URLs, and you stuff every tool description into the context window so the model can pick from the menu. The Model Context Protocol gives agents a standard way to call tools. Skills give them a way to consume instructions. A2A gives them a way to call other agents. All three are useful. All three assume you already know which tool, instruction, or agent you need before the conversation starts.
That assumption is fine at four integrations. It falls apart at forty.
We have written before about the token tax of dumping tool definitions into context, and the math has not gotten friendlier. Every schema you preload is paid for on every turn, whether the agent uses it or not. The toolbelt approach treats the model like a worker who has to wear every tool they might ever need, all at once, all day, and then reason about which one to grab while carrying the full weight of the rest.
So: do not make the model carry the whole tool shed in its backpack. Give it a shelf it can search.
That is the idea behind a draft open specification called Agentic Resource Discovery, or ARD. Hugging Face's launch writeup describes it as a draft developed by contributors from Microsoft, Google, GoDaddy, Hugging Face, and others. ARD is not a replacement for MCP, Skills, or A2A. It is the discovery layer that sits in front of them. It lets an AI client ask a plain question, "what is available for this task?", and lets a discovery service answer with the resources that match. It sits entirely before invocation. Find the resource through ARD, then invoke it through its own native mechanism. ARD is not a product, and it is not a marketplace. It is a way for an agent to find a capability at runtime instead of needing it pre-installed.
On June 17, 2026, Hugging Face shipped a working implementation of that draft, called Hugging Face Discover, with search access to thousands of Skills, ML applications, and MCP servers. So this is no longer a thought experiment about a spec. There is running code.
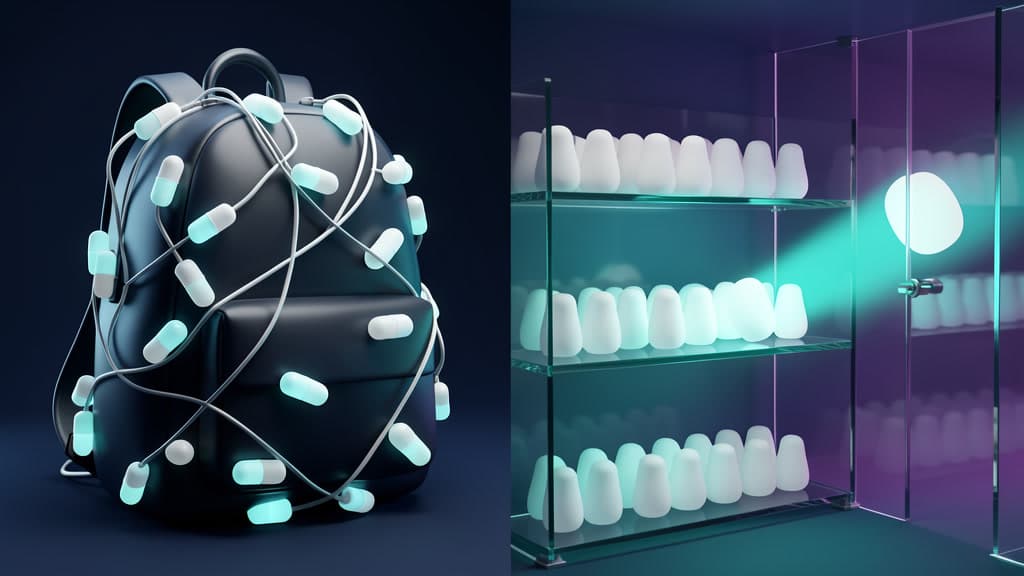
Toolbelt versus shelf, side by side
The difference is where selection happens.
In the toolbelt model, selection happens inside the model. You hand the LLM every option as text and ask it to choose by reading all of them. The model is doing retrieval with the bluntest possible instrument, and you are paying context rent on the full catalog to make that possible.
In the shelf model, selection happens outside the model. The capabilities live in a registry. When the agent has a task, it searches the registry, gets back a ranked set of matches, and only then pulls in the one or two resources it actually picked. The Hugging Face writeup is direct about this: ARD moves selection out of the LLM, where it can use richer signals than a description string. Publisher identity. Representative queries. Compliance attestations. Tags. Things a model cannot infer from a tool name alone.
Concretely, the spec defines two ways to discover. There is ai-catalog.json, a static manifest a publisher can host, and there is POST /search, a dynamic endpoint that returns ranked results for a query. Hugging Face Discover filters to Spaces whose runtime stage is RUNNING, so the agent does not get handed a resource that is currently down. The companion client, hf-discover, is an ARD-compliant client and server, and the command-line examples read about how you would hope:
hf discover search "generate image"
hf discover search "train a biomedical model" --kind skill --json
hf discover search "transcribe some audio" --kind mcp --json
That last one is the tell. Ask for audio transcription and a discovery call can return runnable transcription or speech-generation MCP resources, each with metadata attached, rather than a transcription tool you had to wire in by hand three weeks ago and hope was still live. The agent finds the capability when it needs it, scores the matches, and invokes the winner.
That is the whole move. The toolbelt asks the model to remember everything. The shelf lets the agent look something up.
What goes on the shelf
A toolbelt is just a list of URLs you hardcoded. A shelf is a registry with enough structure that an agent can find the right thing and a human can tell whether it should be there at all.
When we help teams think through this, eight fields do most of the work. The point is not the table. The point is that filling it in forces the questions you were going to hit in production anyway, just earlier and cheaper.
Scroll sideways to see all 8 columns.
| Resource | Type | Owner | Representative query | Trust signal | Access boundary | Invocation path | Retirement rule |
|---|---|---|---|---|---|---|---|
| Whisper Large V3 server | MCP server | Platform team | "transcribe this support call" | Known publisher, runtime stage RUNNING | Reads supplied audio, no transcript storage | Discovery search, then MCP call | Drop if stage leaves RUNNING or unused 90 days |
| Refund policy reference | Skill | Support ops | "what is our refund window for this plan" | Internal attestation, version pinned | Read-only on approved policy docs | Catalog entry, then Skill load | Retire on policy version bump |
| CRM renewal update | Internal API | RevOps | "update the renewal date for this account" | Owner sign-off, approval-gated | Writes one field, human approval required | Approval queue, then logged call | Review every quarter |
| Voice reply generator | MCP server | Platform team | "generate a spoken reply for this ticket" | Known publisher identity | No customer data retained after the call | Discovery search, then MCP call | Retire when superseded by a newer voice model |
Three fields tend to surprise people the first time they fill this in.
The trust signal is the one the toolbelt never had room for. When the agent picks from preloaded descriptions, it is trusting a name. On a shelf, you can require a publisher identity, a compliance attestation, or a runtime status before a resource is even eligible to be returned. That check happens outside the model, which is exactly where you want a trust decision to live.
The invocation path is where governance stops being theoretical. A read-only Skill can be loaded and used freely. An API that writes to your CRM should pass through an approval step and leave a record. If you have been building receipts that log what an agent did after it acts, the invocation path is where you decide which discovered resources require one.
The retirement rule is the field everyone skips and everyone regrets. Resources rot. A model gets deprecated, a Space goes dark, a policy version changes. Without a retirement rule, your searchable shelf slowly turns back into a junk drawer, just a tidier one. Write down the condition that takes each resource off the shelf, before you add the next one.
What to do before the fortieth integration
ARD is a draft specification with one reference implementation, not a finished universal standard, and it is worth being honest about that. The discovery protocols are early. Federated registries that span vendors are mostly still a diagram. You do not need to adopt the spec this quarter.
What you can use today is the shape of the idea. The teams getting into trouble with agents are rarely the ones who picked the wrong tool. They are the ones who never separated "what could this agent reach" from "what is loaded into its head right now." Those are two different questions, and the toolbelt model smashes them into one.
The shelf separates them again. The registry holds everything the agent could reach. Search decides what it pulls in for this task. Selection moves out of the prompt and into a place where you can attach trust signals, access boundaries, and a clean way to retire what no longer belongs. That is also why a capability shelf pairs naturally with the rest of your AI workflow controls: the shelf is the inventory those controls act on.
So before the fortieth integration goes in, try the smaller exercise. Pick one workflow. List every resource it can already reach in the eight columns above. You will almost certainly find a resource nobody owns, an API that writes to a customer record with no approval step, and at least one tool that should have been retired two months ago.
That map is the work. If you want a second set of eyes on it, bring the messiest workflow you have before the next integration becomes context ballast. That is the one with the most to teach you.
NEXT STEP
Turn one crowded workflow into a capability shelf
Use the eight fields in this article to list every resource a single workflow can reach, who owns it, how it gets invoked, and when it should be retired.
The fields are free to copy. The session is for teams that want a second set of eyes before the next integration.
Turn this idea into a pilot
Which workflow should go first?
Use the readiness check to compare impact, effort, risk, owner, and next step before booking a call.
- 3-5 minutes
- Deterministic score
- No sensitive data
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.