A chatbot can be evaluated by reading its answer. An agent needs a receipt.
That difference sounds small until the first production workflow fails. The agent may have written a reasonable summary, but did it read the right document? Did it call the right tool? Did it update the correct record? Did it ask for approval before touching a customer-facing system? Did it recover when an API returned a partial response?
If the evaluation only scores the final paragraph, it misses the work.
OpenAI's evals documentation describes evaluations as tests that check whether model outputs meet criteria you specify. That is a good starting point. But for agentic systems, the output is no longer just text. The output is a sequence of decisions and side effects.
The useful unit to evaluate is the workflow receipt.
What a workflow receipt captures
A workflow receipt is a structured record of what the agent did and why. It should be created whether the run succeeds or fails.
For a sales follow-up agent, the receipt might include:
- input record ID
- retrieved call transcript IDs
- retrieved CRM fields
- generated summary
- proposed email draft
- approval requirement
- reviewer decision
- final action taken
- external API response
- errors and retries
For a support triage agent, it might include:
- incoming ticket ID
- detected intent
- confidence and reason codes
- policy documents consulted
- proposed priority
- routing decision
- human override, if any
- final queue assignment
The point is not to store everything forever. The point is to make the run inspectable enough that a test can ask, "Did this system behave like the workflow requires?"
Model quality is only one layer
A model can produce a good answer inside a bad system.
Imagine an agent that summarizes a refund request perfectly, then writes the summary into the wrong account because the retrieval layer matched the wrong customer. A text-only eval may pass. The customer experience still fails.
Or imagine an agent that drafts a strong reply, but skips the approval step because the prompt said urgent tickets should move quickly. Again, the text may look fine. The process failed.
This is why agent evals should separate at least four layers:
- Did the model interpret the task correctly?
- Did retrieval provide the right source material?
- Did tool use follow the policy?
- Did the workflow end in the right state?
The first layer is a model-output question. The other three are system questions.
Most business value lives in the system questions.
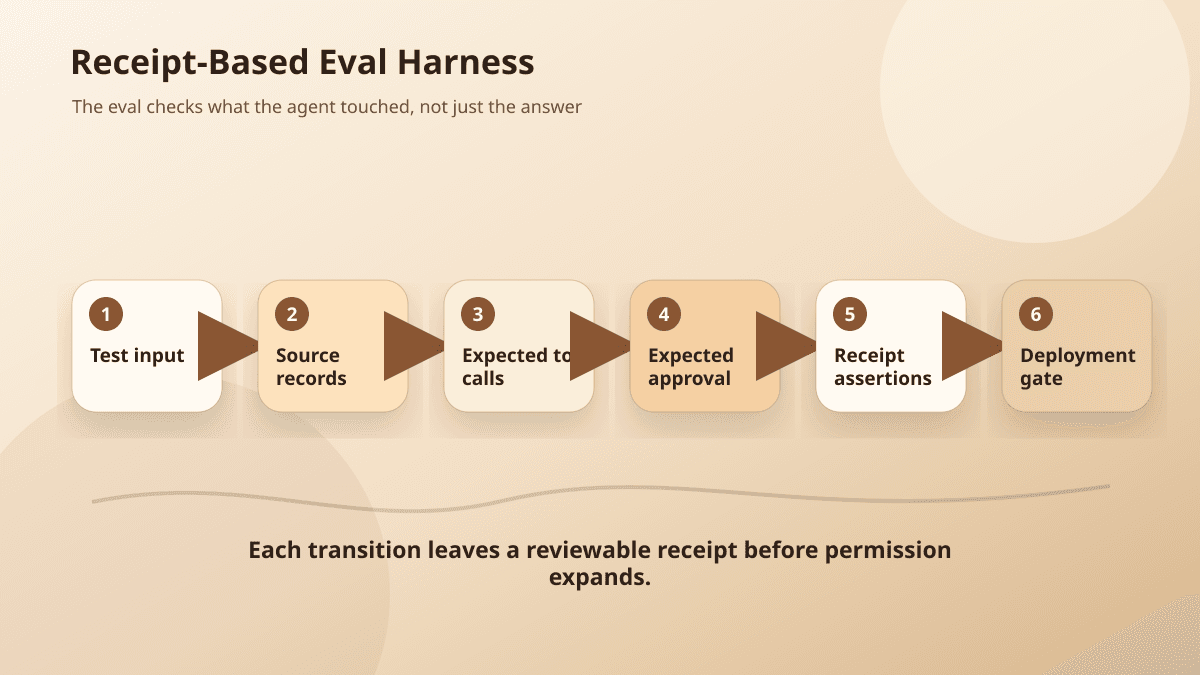
A minimal receipt-based eval
You do not need a complicated harness to start. A simple eval case can include an input fixture, expected receipt conditions, and a few assertions.
{
"case": "refund_request_over_limit",
"input": {
"ticketId": "ticket_1844",
"customerTier": "standard",
"requestedRefund": 1200
},
"expected": {
"mustRetrieve": ["refund_policy_2026"],
"mustNotExecute": ["issue_refund"],
"mustCreate": ["manager_approval_request"],
"finalStatus": "waiting_for_manager"
}
}
The evaluator should not merely ask whether the model says, "This needs approval." It should check whether the system created the approval request and did not issue the refund.
That turns AI quality into software quality.
Receipts make failures less mysterious
When teams first adopt AI agents, failures often get described in vague terms: the model hallucinated, the agent got confused, the automation was unreliable.
A receipt makes the failure concrete.
If the wrong policy was used, retrieval failed. If the right policy was retrieved but ignored, the prompt or planner failed. If the model recommended the right action but the tool executed the wrong one, the integration failed. If the tool returned an error and the agent tried again five times without escalating, recovery logic failed.
Each diagnosis points to a different fix.
Without receipts, teams keep rewriting prompts because prompts are the only artifact they can see.
The receipt becomes your deployment gate
Before a workflow agent touches production, define the receipts that must pass.
For low-risk internal workflows, that may be 20 common cases and 10 failure cases. For customer-facing or regulated workflows, it may be a larger suite with policy edge cases, permission checks, and adversarial inputs.
NIST's AI Risk Management Framework emphasizes mapping, measuring, managing, and governing AI risk. Receipt-based evals make those ideas operational at the workflow level. They show what the system touched, what it decided, and where human oversight entered the loop.
A practical deployment gate might look like this:
- 95% of golden-path receipts reach the expected final state.
- 100% of high-risk actions require approval.
- 0 unauthorized tool calls occur in the test suite.
- All failed API calls produce a recoverable status or human escalation.
- Every customer-facing draft includes the source record used to generate it.
Those gates are not glamorous, but they are the difference between a demo and a system a business can trust.
At BaristaLabs, this is the line we try to draw early: do not ask whether the agent sounded smart. Ask whether the receipt proves the workflow behaved.
Implementation help
Turn agent failures into a regression system
BaristaLabs helps teams convert production misses into locked inputs, expected tool calls, receipt assertions, and review gates before the next release.
Best fit when a demo works, but the team cannot yet explain which failures would block deployment.
Practical AI Workflow Notes
Want more practical AI operations ideas?
Get short notes on applying AI inside real small-business workflows — from document handling and customer follow-up to internal reporting, compliance, and automation guardrails.
Turn this idea into a pilot
Which workflow should go first?
Use the readiness check to compare impact, effort, risk, owner, and next step before booking a call.
- 3-5 minutes
- Deterministic score
- No sensitive data
Share this post